Thoughts on Dremio

Miranda, John Williams Waterhouse, 1916
Software Engineering Daily published a podcast with Tomer Shiran, the founder of Dremio. It was interesting enough that I decided to try something new. This post is just an opinion piece on Dremio and the technology behind it. It's about where it fits in the big data landscape and its potential to make an impact in the industry.
One of the projects I have my eye on is @dremiohq https://t.co/KoHhmV2x2O
— Jowanza Joseph (@Jowanza) November 7, 2017
What Is Dremio?
From the podcast, the marketing material and other content I've found on Dremio, Dremio is hard to define in a sentence. That's because it's a lot of things, and a product targeting a specific group of folks.
“Dremio is a new approach to data analytics. Make your tools better and your teams more productive.”
Dremio is a set of impressive tooling built on top of Apache Arrow and Apache Parquet. It leverages the performance improvements and ergonomic improvements of these platforms, with a query optimizer, and excellent integrations to bring a full-fledged business intelligence tool. That's a lot! However, while using the tool and considering my own use cases every day, it seems like a really smart approach to common problems in data engineering and business intelligence.
Apache Arrow
As far as I can tell, Dremio uses both Apache Arrow and Apache Parquet. In the podcast, a great deal is spoken about Arrow, so I'll focus on that. I wrote about Arrow as one of the most interesting of the data formats going forward. It's columnar like Parquet, ORC, and Carbondata, but it's got a few other optimizations that allow for more limited scans on datasets and its all in memory.

The basic concept of row versus columnar oriented data
The basic idea is that you can represent data in one format and that shared format can be read by a dashboarding tool, Javascript, and Python. Today, if you want to make a Tableau dashboard from a Parquet file you would need some way to translate that Parquet file to something Tableau understood (like ODBC). The hope of Arrow is that Tableau would natively support it, so you can have a compressed, in-memory format that you could share with Tableau, Pandas and Spark, for example.

There is a lot more to arrow than my paragraph. I found this slide deck on Arrow to be informative.
Query Optimizer
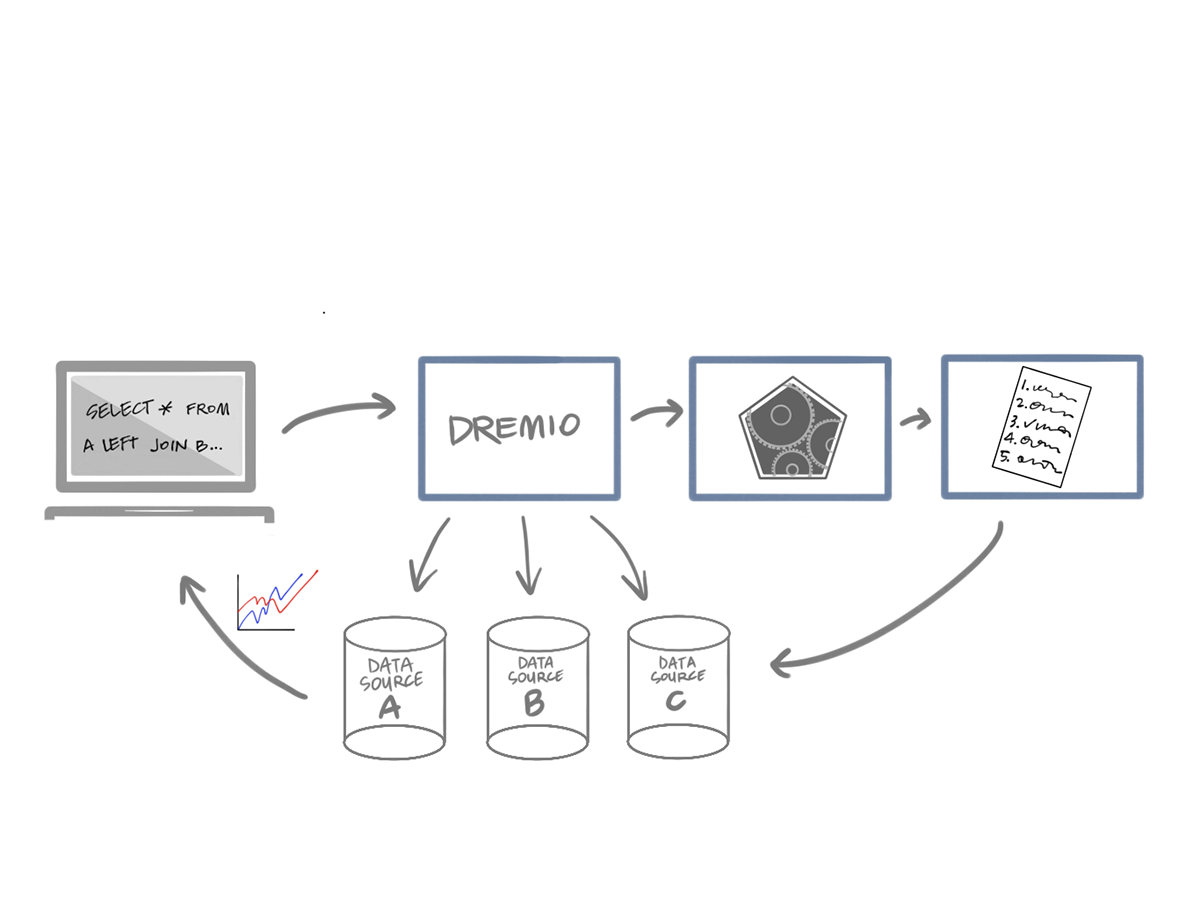
Dremio is more than just an in-memory representation of data, it also has built-in, SQL based query language. This query optimizer is not too different from the SparkSQL's cost-based optimizer or other cost-based optimizers except for a few differences. The biggest difference is something called reflections.
Reflections

An illustration of Dremio Reflections
Reflections are one of the coolest features of Dremio. Reflections are an optimized copy (or partial copy) of data based on queries against data sources. The query optimizer might see that a query against your ElasticSearch cluster could be a lot faster if it were laid out in Arrow. When you perform that query, Dremio will query the Arrow representation instead of data against ElasticSearch. It takes quite a bit of coordination to get something like this to work and not be frustrating, but from trying it out I can report it's pretty dope.
Future
As for deployment, you can deploy Dremio as a standalone or distributed in a number of configurations. I had an easy time using it in local mode, and as a standalone with local disks.
I'm very optimistic about Dremio's future. Dremio is taking a problem (consolidation of in-memory representation of data) and grabbing it by the horns. They are saying, "hey, this is how you can take something like Arrow and make it work for practical use." A future where Apache Arrow is used instead of serializing and deserializing in-memory datasets sounds like a good time. I hope for this future, and it would be cool if Dremio leads it.