Jathena: An Open Source Amazon Athena
Back in July, I presented the work I’ve been doing creating an open source version of Amazon Athena at Open West. The GitHub repo has all of the configurations you need and some nifty gifs of it working. This blog post serves as a written document of my journey and some of the gotchas I experienced along the way.

Starting Point
The starting point was clear to me. I laid out what I thought the Athena architecture roughly was and wrote it all down on paper. I figured I needed a few open source components and narrowed down the list to:
- Object Store
- Distributed SQL Engine
- JDBC Driver
- On Demand Hardware
I knew the first 3 were possible and I wasn’t going to try to tackle the fourth for this project. I just had to pick the right open source version of s3 and I would be on my way. This is what i told myself over the next few weeks of trying and failing to get it to work. Here is my original architecture:
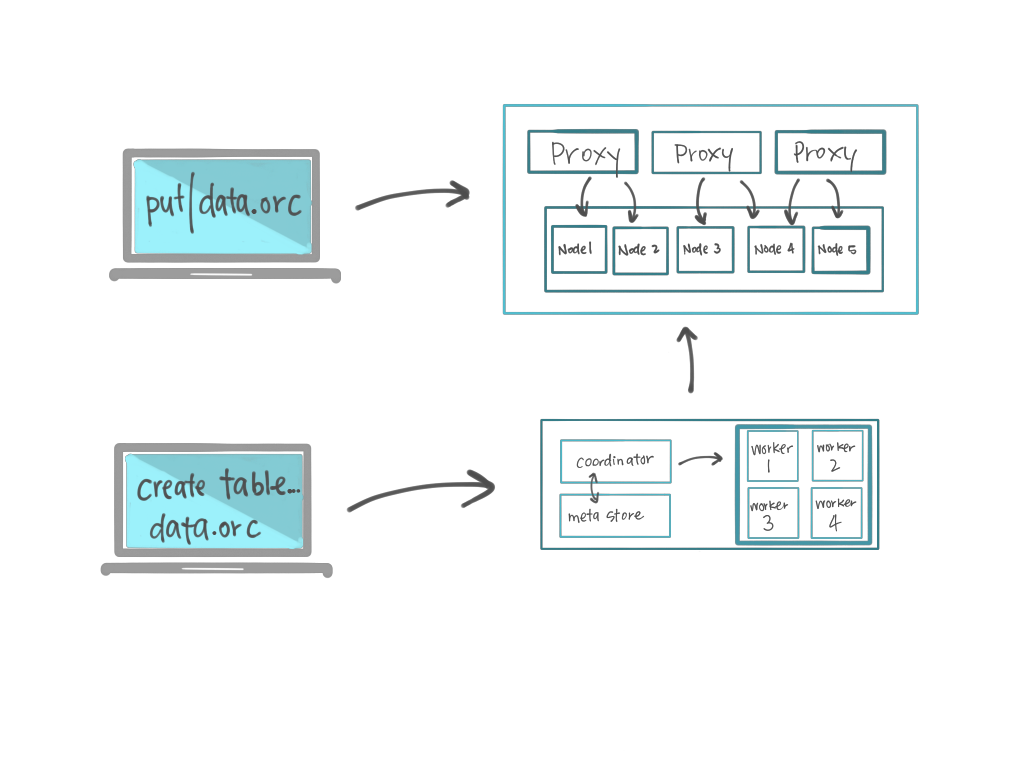
Object Store
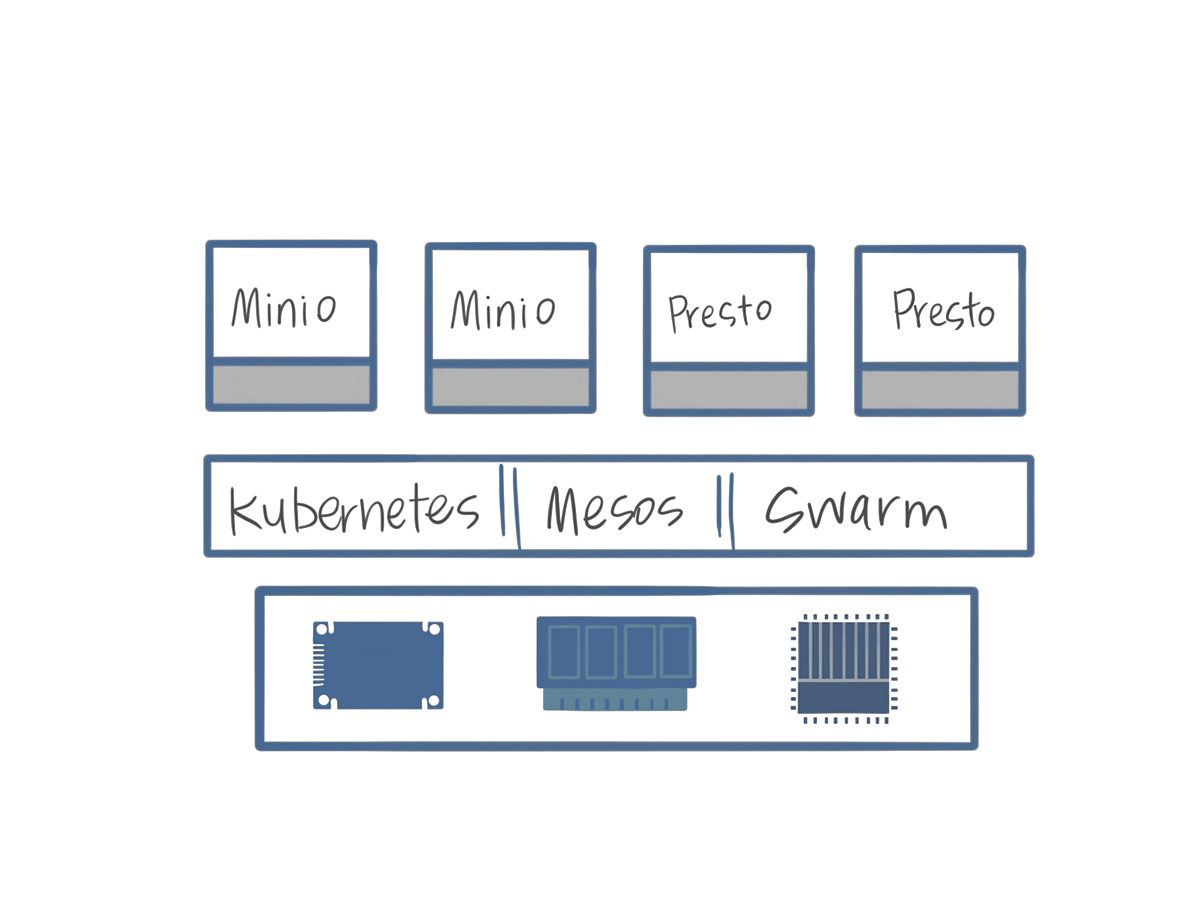
The object store is perhaps the most important piece in this project. Amazon s3 is a so simple but it’s much more extensible and supported than anything else on the market. This is especially true when looking at open source alternatives. I ended up using Minio and I’m very happy with the outcome, especially from starting with OpenStack Swift.
Swift
Swift is the first object store I thought to use with this project, primarily because of talks I listened to about success using it as a Hive store. With my goal to have this project be “cloud native” I quickly found that Swift was not really a good choice. Running OpenStack is non-trivial and all the Python related environmental errors I got didn’t inspire confidence. I did get a version of this project working with Swift, but ultimately didn’t enjoy the latency, object size limitations and the incompatible APIs. I was bummed with how long it took me to get it to work versus what it looked like working. At the time I had not heard of Minio and the prospect of finding another object store was so daunting I found myself in the black hole of Swift source code. Eventually, I found Minio and abandoned this effort.
Minio
Once I gave up on Swift, Minio was the best I could find. In all the docs I read, there wasn't a ton about using it with the big data ecosystem which was concerning. I did read a lot about it being an s3 compatible API and I found some obscure usage with Spark so I went forward. Actually installing and getting it to deploy and scale out on Kubernetes was easy (perhaps too easy). Getting it to work with Presto was a different story. I messed around with different versions and configurations in Presto and finally got it to work.
Presto
Before I jump into this any further, I will say that Presto is really nice. It has its own scheduler and it’s got pretty impressive tooling and connectors. It was fairly easy to get deployed onto Kubernetes, but tricky to get working with s3 compliant storage. I got it to work, but was ultimately unhappy with it for reasons that are not explicitly technical. Suffice it to say, I didn’t feel extendible in the ways I wanted for this project. Once I started looking elsewhere for a distributed query engine I found trade offs that I was more comfortable with.
Apache Drill

After working with Drill on this project, I’m completely embarrassed that I haven’t given Drill a serious look before this point. It works with a wide array of technology and it’s incredibly configurable and fun to use. The key downside to Drill is having to use Apache Zookeeper if you run it in closer mode. I haven’t had issues with Zookeeper on any project I’ve used it, but it is seen as a weakness in almost every project that uses it so I am going to mention it here. Zookeeper also makes it more difficult to deploy. The more moving pieces, the worse operability the system is to have and making this choice adds that overhead. The drill UI, it’s ease of setup and the ergonomics of actually querying with Drill all made it worth it to use.
Kubernetes
I could have potentially done this project with Mesos, or Docker Swarm, but I’m glad I went with Kubernetes instead. I wanted a project to cut my teeth with Kubernetes on and this was a great one. I had to actually dig into a lot of docker machines, learn helm and understand a bit more about what goes on behind the scenes in order to get everything to work together. With some persistence I got it all working and deployed with just one command.

The Name
I called this project Jathena as a joke, adding the first initial of my name onto Athena. I was too lazy to think of a better name and since it’s a proof of concept the name is good enough.
To-do
I probably won’t work on this anymore given it was a proof of concept and I proved the concept. Ideally, setting up s3 without having to paste a config would be nice.
Thanks
This was pretty long, thanks for reading it. If you have any code suggestions please set that up on the git repo. Like I said, It’s a proof of concept so I’m probably going to leave it where it is but I always appreciate a good piece of advice.